논문 선정
강필성 교수님의 비즈니스 어낼리틱스 수업의 세번째 논문 구현 주제는 Anomaly Detection이다. Anomaly Detection 방법론 중 GAN을 활용하여
Anomaly Detection을 수행하는 AnoGAN을 2년 전에 공부를 하며 코딩을 해두었는데 이번 기회에 다시 한 번 코드를 정리할 겸 추가적인 공부를 하기 위해 아래의 논문을 선정하였다.

Schlegl, T., Seeböck, P., Waldstein, S. M., Schmidt-Erfurth, U., & Langs, G. (2017, June). Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In International conference on information processing in medical imaging (pp. 146-157). Springer, Cham.
AnoGAN 기본 구조 (학습)
Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery 논문에서 소개 된 AnoGAN은 Deep Convolutional Generative Adversarial Network (DCGAN)의 구조를 활용하여 정상 데이터의 latent space로 적절하게 매핑이 되는지 여부를 통해 Anomaly Detection을 수행하는 방법론이다. 아래는 일반적인 DCGAN의 구조와 t-SNE embedding으로 정상(파란색), 비정상(빨간색)를 나타낸다.
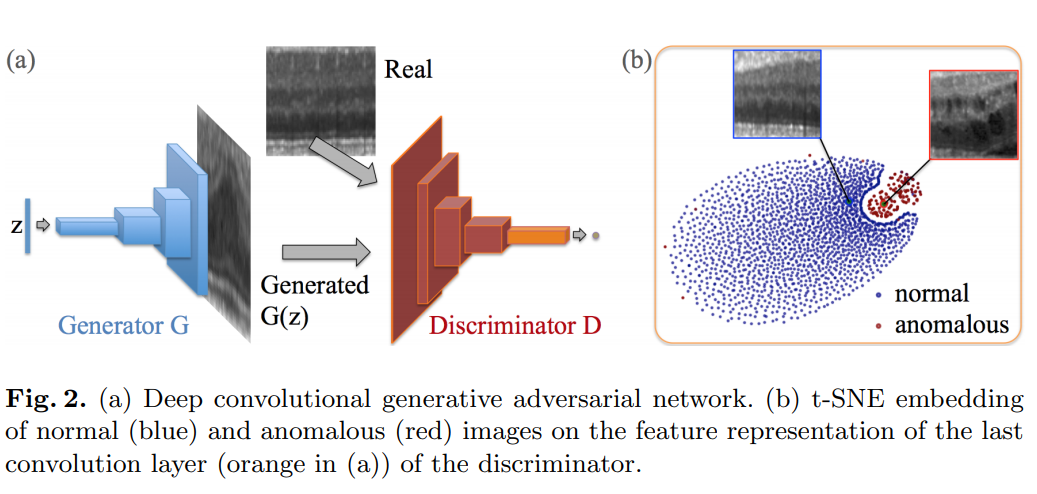
- Generator \(G\) : \(G(z) = z \rightarrow x\) 매핑을 통하여 \(x\)로부터 distribution \(p_g\)를 학습, 이 경우 Convolutional decoder
- samples \(z\) : Latent space \(Z\)로부터 샘플링 된 1차원의 vector (일반적으로 uniform distribution을 따르는 noise)
- Image patch \(x\) : image space manifold \(X\)안의 우리가 가지고 있는 정상 이미지 데이터
- Discriminator \(D\) : 일반적인 CNN 구조로 2D images를 받아서 scalar value \(D(\cdot)\)으로 매핑, 원본 이미지와 Generator로부터 생긴 이미지를 구분
DCGAN은 GAN이 잘 학습되었다고 했을 때, \(z\)는 데이터들을 잘 압축하고 있다고 할 수 있다. 즉, \(z\)의 값들을 연속적으로 변화시키면 이에 맞춰 생성되는 이미지 또한 연속적으로 변화한다. 따라서 먼저 정상 데이터들을 사용해서 일반적인 DCGAN을 학습시키고 만약 GAN이 수렴했다면, 정상 데이터의 latent space, (위의 파란색) manifold \(X\)를 학습했다고 할 수 있다.
DCGAN 기본구조 Code
import tensorflow as tf
def generator(z_in, use_batchnorm=True, use_bias=True):
reuse = tf.AUTO_REUSE
xavier_init, xavier_init_conv = tf.contrib.layers.xavier_initializer(uniform=True), tf.contrib.layers.xavier_initializer_conv2d(uniform=True)
with tf.variable_scope('generator', reuse=reuse):
net = tf.layers.dense(inputs=z_in, units=7*7*32, kernel_initializer=xavier_init, use_bias=use_bias, name='layer1/dense', reuse=reuse)
net = tf.reshape(net, (-1, 7, 7, 32), name='layer1/reshape')
if use_batchnorm:
net = tf.layers.batch_normalization(inputs=net, training=is_train, axis=3, name='layer1/batchnorm', reuse=reuse)
net = tf.nn.leaky_relu(net, name='layer1/act')
net = tf.layers.conv2d_transpose(inputs=net, filters=16, kernel_size=(3, 3), strides=(2, 2), use_bias=use_bias, padding='same',
kernel_initializer=xavier_init_conv, name='layer2/convtr', reuse=reuse)
if use_batchnorm:
net = tf.layers.batch_normalization(inputs=net, training=is_train, axis=3, name='layer2/batchnorm', reuse=reuse)
net = tf.nn.leaky_relu(net, name='layer2/act')
net = tf.layers.conv2d_transpose(inputs=net, filters=8, kernel_size=(3, 3), strides=(2, 2), use_bias=use_bias, padding='same',
kernel_initializer=xavier_init_conv, name='layer3/convtr', reuse=reuse)
if use_batchnorm:
net = tf.layers.batch_normalization(inputs=net, training=is_train, axis=3, name='layer3/batchnorm', reuse=reuse)
net = tf.nn.leaky_relu(net, name='layer3/act')
net = tf.layers.conv2d_transpose(inputs=net, filters=1, kernel_size=(3, 3), strides=(1, 1), use_bias=use_bias, padding='same',
kernel_initializer=xavier_init_conv, name='layer4/output', reuse=reuse)
return tf.tanh(net)
def discriminator(x_in, use_batchnorm=False, use_bias=True):
reuse = tf.AUTO_REUSE
xavier_init_conv = tf.contrib.layers.xavier_initializer_conv2d(uniform=True)
with tf.variable_scope('discriminator', reuse=reuse):
net = tf.layers.conv2d(inputs=x_in, filters=16, kernel_size=(3, 3), strides=(2, 2), use_bias=use_bias, padding='same',
kernel_initializer=xavier_init_conv, name='layer1/conv', reuse=reuse)
if use_batchnorm:
net = tf.layers.batch_normalization(inputs=net, training=is_train, axis=3, name='layer1/batchnorm', reuse=reuse)
net = tf.nn.leaky_relu(net, name='layer1/act')
net = tf.layers.conv2d(inputs=net, filters=32, kernel_size=(3, 3), strides=(2, 2), use_bias=use_bias, padding='same',
kernel_initializer=xavier_init_conv, name='layer2/conv', reuse=reuse)
if use_batchnorm:
net = tf.layers.batch_normalization(inputs=net, training=is_train, axis=3, name='layer2/batchnorm', reuse=reuse)
net = tf.nn.leaky_relu(net, name='layer2/act')
net = tf.layers.flatten(net, name='layer3/act')
net = tf.layers.dense(inputs=net, units=1, name='layer3/output')
return net
def chunks(l, n):
for i in range(0, len(l), n):
yield l[i:i+n]
z_dim = 50
is_train = tf.placeholder(tf.bool, name='is_train')
z = tf.placeholder(dtype=tf.float32, shape=[None, z_dim], name='z')
x = tf.placeholder(dtype=tf.float32, shape=[None, 28, 28, 1])
G = generator(z)
D_real, D_fake = discriminator(x), discriminator(G)
d_loss_real = tf.nn.sigmoid_cross_entropy_with_logits(logits=D_real, labels=tf.ones_like(D_real))
d_loss_fake = tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake, labels=tf.zeros_like(D_fake))
g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake, labels=tf.ones_like(D_fake)))
d_loss = tf.reduce_mean(d_loss_real) + tf.reduce_mean(d_loss_fake)
d_acc = tf.reduce_mean(tf.cast(tf.equal(tf.concat([tf.ones_like(D_real, tf.int32), tf.zeros_like(D_fake, tf.int32)], 0),
tf.concat([tf.cast(tf.greater(D_real, 0.5), tf.int32), tf.cast(tf.greater(D_fake, 0.5), tf.int32)], 0)), tf.float32))
g_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='generator')
d_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='discriminator')
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
d_update_ops = [var for var in update_ops if 'discriminator' in var.name]
g_update_ops = [var for var in update_ops if 'generator' in var.name]
with tf.control_dependencies(d_update_ops):
d_opt1 = tf.train.AdamOptimizer(learning_rate=1E-3, name='D-optimizer-1').minimize(loss=d_loss, var_list=d_vars)
d_opt2 = tf.train.AdamOptimizer(learning_rate=1E-4, name='D-optimizer-2').minimize(loss=d_loss, var_list=d_vars)
with tf.control_dependencies(g_update_ops):
g_opt1 = tf.train.AdamOptimizer(learning_rate=1E-3, name='G-optimizer-1').minimize(loss=g_loss, var_list=g_vars)
g_opt2 = tf.train.AdamOptimizer(learning_rate=1E-4, name='G-optimizer-2').minimize(loss=g_loss, var_list=g_vars)
AnoGAN 기본 구조 (테스트)
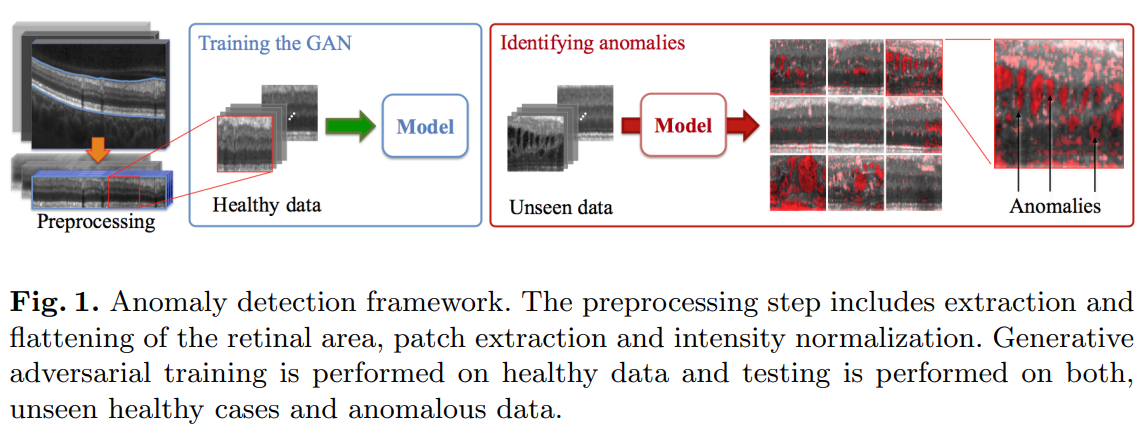
DCGAN의 학습이 완료되었다면 테스트를 통해 궁금한 데이터의 정상 여부를 판단해야 한다. 하지만 \(\mathbf{z} \rightarrow \mathbf{x}\)로 매핑하는 것은 Generator \(G(\mathbf{z}) = \mathbf{z} \rightarrow \mathbf{x}\)를 통하여 가능하지만 그 반대의 상황인 원본 이미지를 통해 \(\mathbf{x} \rightarrow \mathbf{z}\)로 매핑하는 것은 어렵다. 즉, 원본 이미지를 통해 latent space \(\mathbf{z}\)로 매핑하는 작업(\(G^{-1}(\mathbf{x}) = \mathbf{x} \rightarrow \mathbf{z}\))을 \(G\)와 \(D\)만으로는 할 수가 없다.
그래서 AnoGAN은 query image \(\mathbf{x}\)가 주어졌을때, 해당 이미지 \(\mathbf{x}\)와 가장 유사한 이미지 \(G(\mathbf{z})\)를 생성하는 \(\mathbf{z}\)를 찾아낸다. 가장 최적화된 \(\mathbf{z}\)를 찾기 위해서 먼저 학습과정에서 사용한 분포 \(\mathbf{p_z}\)에서 임의의 노이즈 \(\mathbf{z_1}\)을 추출하고 \(G(\mathbf{z_1})\)을 통해 가짜 이미지를 생성한다. 이렇게 만들어 낸 이미지에서 Residual Loss 그리고 Discrimination Loss로 이루어 진 loss function을 통해 gradients를 계산하고 backpropagation을 통해서 \(\mathbf{z_1}\)의 coefficients를 업데이트한다. 이렇게 만들어진 값이 다시 \(\mathbf{z_2}\)가 되고 이 과정을 반복하여 얻어진 \(G(\mathbf{z}_\gamma)\)이 \(\mathbf{x}\)와 얼마나 유사했는지를 판단하여 정상 여부를 결정한다. 이때 이 과정은 \(G\)와 \(D\)의 parameter들은 고정한 상태에서 진행된다. 결과적으로 query image \(\mathbf{x}\)가 정상 데이터라면 latent space로의 매핑이 가능해 loss가 적게 발생하겠지만 비정상 데이터라면 큰 차이의 loss가 생기게 된다.
좀 더 구체적으로 Residual Loss 그리고 Discrimination Loss로 이루어 진 loss function을 설명해보자.
Residual Loss
Residual Loss는 Generator로 부터 만들어 낸 image(\(G(\mathbf{z}_\gamma)\))와 query image \(\mathbf{x}\) 간의 시각적 차이를 나타낸다. 이는 아래의 식으로 표현할 수 있다.
\[L_R \left(\mathbf{z}_{\gamma} \right) = \sum \big|\ \mathbf{x} - G(\mathbf{z}_\gamma) \ \big|\]만약 완벽한 \(G\)를 통해 latent space로 완전한 대응이 가능하다면 정상 이미지 \(\mathbf{x}\)가 입력되었을 때, \(\mathbf{x}\)와 \(G(\mathbf{z}_\gamma)\)는 동일하게 되어 Residual loss는 0이 된다. 코드로는 Residual Loss를 다음과 같이 표현할 수 있다.
residual_loss = tf.reduce_mean(tf.abs(target_x - mapped_x), axis=[1, 2, 3])
Discrimination Loss
Discriminator \(D\)의 역할은 Generator로부터 생성된 가짜 이미지인지 진짜 원본 이미지인지를 판단하는 것이다. 즉, \(D\)는 학습 데이터의 분포를 파악하는 역할을 한다고 생각할 수 있다. AnoGAN의 Discrimination loss는 Generator로 부터 만들어 낸 image(\(G(\mathbf{z}_\gamma)\))가 manifold 혹은 데이터의 분포에 잘 위치하도록 페널티를 부과하는 역할을 한다. 즉 Discrimination loss값을 구해서 \(\mathbf{z}_\gamma\)를 업데이트하는데 사용된다.
\[L_D(\mathbf{z}_\gamma) = \sum \big\| \mathbf{f}(\mathbf{x}) - \mathbf{f}(G(\mathbf{z}_\gamma)) \big\|\]\(\mathbf{f}\)는 feature mapping에서 나온 개념으로 discriminator의 중간층에 있는 activations들을 가르킨다. 즉 AnoGAN은 Discriminator \(D\)의 최종 출력(0 또는 1)을 사용하지 않고 중간 레이어에서의 결과값을 통해 Discrimination loss를 구성한다. 논문에서는 이 discriminator의 중간층에 있는 activations들이 더 풍부한 표현력을 가지고 있기 때문이라고 설명한다. 코드로는 Discrimination Loss를 다음과 같이 표현할 수 있다.
discrimination_loss = tf.reduce_mean(tf.abs(target_d_feature - mapped_d_feature), axis=[1, 2, 3])
최종 loss는 이 둘의 weighted sum이다.
\[L(\mathbf{z}_\gamma) = (1-\lambda) \cdot L_R(\mathbf{z}_\gamma) + \lambda \cdot L_D (\mathbf{z}_\gamma)\]로 표현한다. 위의 loss를 바탕으로 backpropagation 방식으로 \(\mathbf{z}_\gamma\)를 업데이트시킨다. 즉 \(G\)와 \(D\) parameter들은 고정된 상태로 \(\mathbf{z}\)의 coefficients를 업데이트한다. 일정 횟수 동안 업데이트가 진행되면 마지막으로 loss를 구한다음, 이 loss가 특정값 미만이면 정상, 특정값 이상이면 비정상으로 판단하게 된다. 즉, 낮은 loss는 입력과 유사한 데이터를 학습 과정에서 봤고, manifold에 적절한 매핑이 가능하다는 의미지만, 높은 loss는 적절한 매핑을 찾는데 실패했다는 의미로 해석할 수 있다. 논문에서는 총 500번 \(\mathbf{z}\)의 coefficients를 업데이트하는 과정을 수행하였고 두 loss의 weight parameter로 작용하는 \(\lambda\)는 0.1로 설정했다. 코드로 전체 Loss를 표현하면 다음과 같다.
mapping_loss = (1-lam)*residual_loss + lam*discrimination_loss
Anomaly Detection with AnoGAN (python 3.6, tensorflow 1.15)
앞서 소개한대로 DCGAN의 일반적인 구조에 AnoGAN의 최종 loss를 추가하여 Anomaly Detection을 수행하는 코드는 다음과 같다. 먼저 정상 데이터들로 DCGAN을 학습시키고,
import tensorflow as tf
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data/', one_hot=False, reshape=False)
def generator(z_in, use_batchnorm=True, use_bias=True):
reuse = tf.AUTO_REUSE
xavier_init, xavier_init_conv = tf.contrib.layers.xavier_initializer(uniform=True), tf.contrib.layers.xavier_initializer_conv2d(uniform=True)
with tf.variable_scope('generator', reuse=reuse):
net = tf.layers.dense(inputs=z_in, units=7*7*32, kernel_initializer=xavier_init, use_bias=use_bias, name='layer1/dense', reuse=reuse)
net = tf.reshape(net, (-1, 7, 7, 32), name='layer1/reshape')
if use_batchnorm:
net = tf.layers.batch_normalization(inputs=net, training=is_train, axis=3, name='layer1/batchnorm', reuse=reuse)
net = tf.nn.leaky_relu(net, name='layer1/act')
net = tf.layers.conv2d_transpose(inputs=net, filters=16, kernel_size=(3, 3), strides=(2, 2), use_bias=use_bias, padding='same',
kernel_initializer=xavier_init_conv, name='layer2/convtr', reuse=reuse)
if use_batchnorm:
net = tf.layers.batch_normalization(inputs=net, training=is_train, axis=3, name='layer2/batchnorm', reuse=reuse)
net = tf.nn.leaky_relu(net, name='layer2/act')
net = tf.layers.conv2d_transpose(inputs=net, filters=8, kernel_size=(3, 3), strides=(2, 2), use_bias=use_bias, padding='same',
kernel_initializer=xavier_init_conv, name='layer3/convtr', reuse=reuse)
if use_batchnorm:
net = tf.layers.batch_normalization(inputs=net, training=is_train, axis=3, name='layer3/batchnorm', reuse=reuse)
net = tf.nn.leaky_relu(net, name='layer3/act')
net = tf.layers.conv2d_transpose(inputs=net, filters=1, kernel_size=(3, 3), strides=(1, 1), use_bias=use_bias, padding='same',
kernel_initializer=xavier_init_conv, name='layer4/output', reuse=reuse)
return tf.tanh(net)
def discriminator(x_in, use_batchnorm=False, use_bias=True):
reuse = tf.AUTO_REUSE
xavier_init_conv = tf.contrib.layers.xavier_initializer_conv2d(uniform=True)
with tf.variable_scope('discriminator', reuse=reuse):
net = tf.layers.conv2d(inputs=x_in, filters=16, kernel_size=(3, 3), strides=(2, 2), use_bias=use_bias, padding='same',
kernel_initializer=xavier_init_conv, name='layer1/conv', reuse=reuse)
if use_batchnorm:
net = tf.layers.batch_normalization(inputs=net, training=is_train, axis=3, name='layer1/batchnorm', reuse=reuse)
net = tf.nn.leaky_relu(net, name='layer1/act')
net = tf.layers.conv2d(inputs=net, filters=32, kernel_size=(3, 3), strides=(2, 2), use_bias=use_bias, padding='same',
kernel_initializer=xavier_init_conv, name='layer2/conv', reuse=reuse)
if use_batchnorm:
net = tf.layers.batch_normalization(inputs=net, training=is_train, axis=3, name='layer2/batchnorm', reuse=reuse)
net = tf.nn.leaky_relu(net, name='layer2/act')
net = tf.layers.flatten(net, name='layer3/act')
net = tf.layers.dense(inputs=net, units=1, name='layer3/output')
return net
def chunks(l, n):
for i in range(0, len(l), n):
yield l[i:i+n]
z_dim = 50
is_train = tf.placeholder(tf.bool, name='is_train')
z = tf.placeholder(dtype=tf.float32, shape=[None, z_dim], name='z')
x = tf.placeholder(dtype=tf.float32, shape=[None, 28, 28, 1])
G = generator(z)
D_real, D_fake = discriminator(x), discriminator(G)
d_loss_real = tf.nn.sigmoid_cross_entropy_with_logits(logits=D_real, labels=tf.ones_like(D_real))
d_loss_fake = tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake, labels=tf.zeros_like(D_fake))
g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake, labels=tf.ones_like(D_fake)))
d_loss = tf.reduce_mean(d_loss_real) + tf.reduce_mean(d_loss_fake)
d_acc = tf.reduce_mean(tf.cast(tf.equal(tf.concat([tf.ones_like(D_real, tf.int32), tf.zeros_like(D_fake, tf.int32)], 0),
tf.concat([tf.cast(tf.greater(D_real, 0.5), tf.int32), tf.cast(tf.greater(D_fake, 0.5), tf.int32)], 0)), tf.float32))
g_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='generator')
d_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='discriminator')
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
d_update_ops = [var for var in update_ops if 'discriminator' in var.name]
g_update_ops = [var for var in update_ops if 'generator' in var.name]
with tf.control_dependencies(d_update_ops):
d_opt1 = tf.train.AdamOptimizer(learning_rate=1E-3, name='D-optimizer-1').minimize(loss=d_loss, var_list=d_vars)
d_opt2 = tf.train.AdamOptimizer(learning_rate=1E-4, name='D-optimizer-2').minimize(loss=d_loss, var_list=d_vars)
with tf.control_dependencies(g_update_ops):
g_opt1 = tf.train.AdamOptimizer(learning_rate=1E-3, name='G-optimizer-1').minimize(loss=g_loss, var_list=g_vars)
g_opt2 = tf.train.AdamOptimizer(learning_rate=1E-4, name='G-optimizer-2').minimize(loss=g_loss, var_list=g_vars)
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
sess.run(tf.global_variables_initializer())
train_dat = mnist.train.images*2 - 1
n_train = len(train_dat)
max_epoch = 200
minibatch_size = 256
pbar = tqdm(range(max_epoch))
d_opt, g_opt = d_opt1, g_opt1
g_loss_traj, d_loss_traj = [], []
for epoch in pbar:
train_idx = np.arange(n_train)
np.random.shuffle(train_idx)
train_batch = chunks(train_idx, minibatch_size)
if epoch == 150:
d_opt, g_opt = d_opt2, g_opt2
g_loss_stack, d_loss_stack, d_acc_stack = [], [], []
for batch_idx in train_batch:
batch_x = train_dat[batch_idx]
batch_z = np.random.uniform(-1, 1, size=[len(batch_idx), z_dim])
D_loss, D_acc, _ = sess.run([d_loss, d_acc, d_opt], feed_dict={x: batch_x, z: batch_z, is_train: True})
_ = sess.run(g_opt, feed_dict={z: batch_z, is_train: True})
G_loss, _ = sess.run([g_loss, g_opt], feed_dict={z: batch_z, is_train: True})
g_loss_stack.append(G_loss)
d_loss_stack.append(D_loss)
d_acc_stack.append(D_acc)
g_loss_traj.append(np.mean(g_loss_stack))
d_loss_traj.append(np.mean(d_loss_stack))
pbar.set_description('G-loss: {:.4f} | D-loss: {:.4f} | D-accuracy: {:.4f}'.format(np.mean(g_loss_stack), np.mean(d_loss_stack), np.mean(d_acc_stack)))
plt.plot(g_loss_traj); plt.plot(d_loss_traj); plt.show()
batch_z = np.random.uniform(-1, 1, size=[16, z_dim])
samples = sess.run(G, feed_dict={z: batch_z, is_train: False})
plt.figure(figsize=(10, 10))
for i, sample in enumerate(samples):
plt.subplot(4, 4, i+1)
plt.imshow(sample.reshape(28, 28), cmap='gray')
plt.show()
DCGAN의 학습과정에서 얻어진 분포 \(\mathbf{p_z}\)에서 임의의 노이즈 \(\mathbf{z}\)을 추출하고 \(G\)와 \(D\)의 parameter들은 고정한 상태에서 \(\mathbf{z}\)의 coefficients를 업데이트하는 과정을 일정 횟수 반복한 뒤, 최종적으로 얻어진 \(\mathbf{z}_\gamma\)로부터 생성 된 \(G(\mathbf{z}_\gamma)\)이 \(\mathbf{x}\)와 얼마나 유사했는지를 판단하여 정상 여부를 결정한다. 즉, 정상 데이터의 latent space로 적절하게 매핑이 되는지 여부를 통해 데이터의 정상여부를 판단한다.
### AnoGAN - mapping new observations to the latent space
def get_discriminator_feature(x_in, use_batchnorm=False, use_bias=True):
reuse = True
xavier_init_conv = tf.contrib.layers.xavier_initializer_conv2d(uniform=True)
with tf.variable_scope('discriminator', reuse=reuse):
net = tf.layers.conv2d(inputs=x_in, filters=16, kernel_size=(3, 3), strides=(2, 2), use_bias=use_bias, padding='same',
kernel_initializer=xavier_init_conv, name='layer1/conv', reuse=reuse)
if use_batchnorm:
net = tf.layers.batch_normalization(inputs=net, training=False, axis=3, name='layer1/batchnorm', reuse=reuse)
net = tf.nn.leaky_relu(net, name='layer1/act')
return net
target_x = tf.placeholder(dtype=tf.float32, shape=[1, 28, 28, 1], name='target_x')
target_z = tf.get_variable('anogan/target_z', shape=[1, z_dim], initializer=tf.random_uniform_initializer(-1, 1), trainable=True)
mapped_x = generator(target_z)
target_d_feature = get_discriminator_feature(target_x)
mapped_d_feature = get_discriminator_feature(mapped_x)
lam = 0.7
anogan_var = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='anogan')
residual_loss = tf.reduce_mean(tf.abs(target_x - mapped_x), axis=[1, 2, 3])
discrimination_loss = tf.reduce_mean(tf.abs(target_d_feature - mapped_d_feature), axis=[1, 2, 3])
mapping_loss = (1-lam)*residual_loss + lam*discrimination_loss
mapping_loss_opt1 = tf.train.AdamOptimizer(learning_rate=1E-1, name='mapping-optimizer-1').minimize(loss=mapping_loss, var_list=anogan_var)
mapping_loss_opt2 = tf.train.AdamOptimizer(learning_rate=1E-2, name='mapping-optimizer-2').minimize(loss=mapping_loss, var_list=anogan_var)
uninitialized_variables = [var for var in tf.global_variables() if not(sess.run(tf.is_variable_initialized(var)))]
sess.run(tf.variables_initializer(uninitialized_variables))
query_x = mnist.test.images[2].reshape(1, 28, 28, 1)
sess.run(tf.variables_initializer(anogan_var))
mapping_loss_traj = []
mapping_loss_opt = mapping_loss_opt1
for i in range(150):
if i == 50:
mapping_loss_opt = mapping_loss_opt2
loss, _ = sess.run([mapping_loss, mapping_loss_opt], feed_dict={target_x: query_x, is_train: False})
mapping_loss_traj.extend(loss)
anomaly_score = mapping_loss[-1]
### Comparison of Query Image and Mapped Image
generated_x = sess.run(generator(target_z), feed_dict={is_train: False})
plt.figure(figsize=(14, 4))
plt.subplot(1, 3, 1)
plt.imshow(generated_x.reshape(28, 28), cmap='gray')
plt.title('Mapped Image')
plt.subplot(1, 3, 2)
plt.imshow(query_x.reshape(28, 28), cmap='gray')
plt.title('Query Image')
plt.subplot(1, 3, 3)
plt.plot(mapping_loss_traj)
plt.title('Mapping loss per iteration')
plt.show()
plt.close()
결론
이번 논문 구현 과제를 통해 오래 전에 작성한 코드와 논문을 다시 복습할 수 있는 기회를 가졌다. 당시 GAN과 Auto-Encoder 관련 논문을 읽고 코드로 구현을 해두었는데 시간이 지나니 많은 부분 기억이 잘 나지 않아 다시 공부를 해야 했다. 추후 시간이 날 때마다 AnoGAN 뿐만 아니라 구현해두었던 InfoGAN, Wasserstein GAN, Bidectional GAN, VAE, AAE 등을 정리하여 포스팅해두어야 겠다.
참고문헌
- Schlegl, T., Seeböck, P., Waldstein, S. M., Schmidt-Erfurth, U., & Langs, G. (2017, June). Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In International conference on information processing in medical imaging (pp. 146-157). Springer, Cham.
- Radford, A., Metz, L., & Chintala, S. (2015). Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434.